Abstract
Spectral Graph Pruning (SGP) is a framework for efficient context optimization and compression in Retrieval-Augmented Generation (RAG). It models retrieved text segments as a heterogeneous semantic graph and applies query-biased spectral centrality analysis to identify and retain the most structurally important segments. SGP reduces token consumption by 40-50% while maintaining high reasoning accuracy on multi-hop benchmarks.
Methodology
The SGP framework constructs a heterogeneous graph representing Chunk Nodes, Entity Nodes, and Structural document hierarchy.
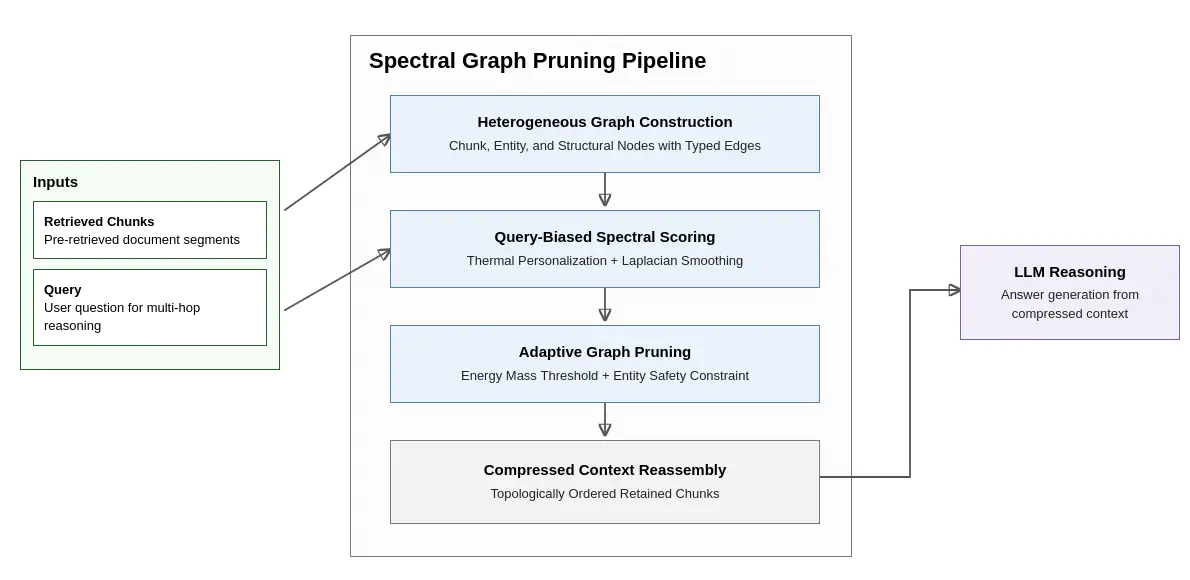 Figure 1: SGP Pipeline: From heterogeneous graph construction to energy-mass pruning.
Figure 1: SGP Pipeline: From heterogeneous graph construction to energy-mass pruning.
Key Contributions
- Context Graph Construction: Models raw text chunks, extracted entities, and document hierarchy as nodes in a unified graph.
- Spectral Centrality: Uses the graph Laplacian to compute query-biased node importance.
- Adaptive Pruning: Detects the “elbow” in cumulative importance to retain only the minimal topological backbone required for reasoning.
Evaluation and Results
SGP was evaluated on HotpotQA and MuSiQue benchmarks, demonstrating superior performance-to-compression ratios.
| Method | Token F1 | Exact Match | Compression |
|---|---|---|---|
| Full Context | 74.7% | 62.5% | 0.0% |
| Dense Retrieval | 68.7% | 58.0% | 51.8% |
| SGP (Ours) | 70.6% | 61.0% | 47.7% |
Performance Trade-offs
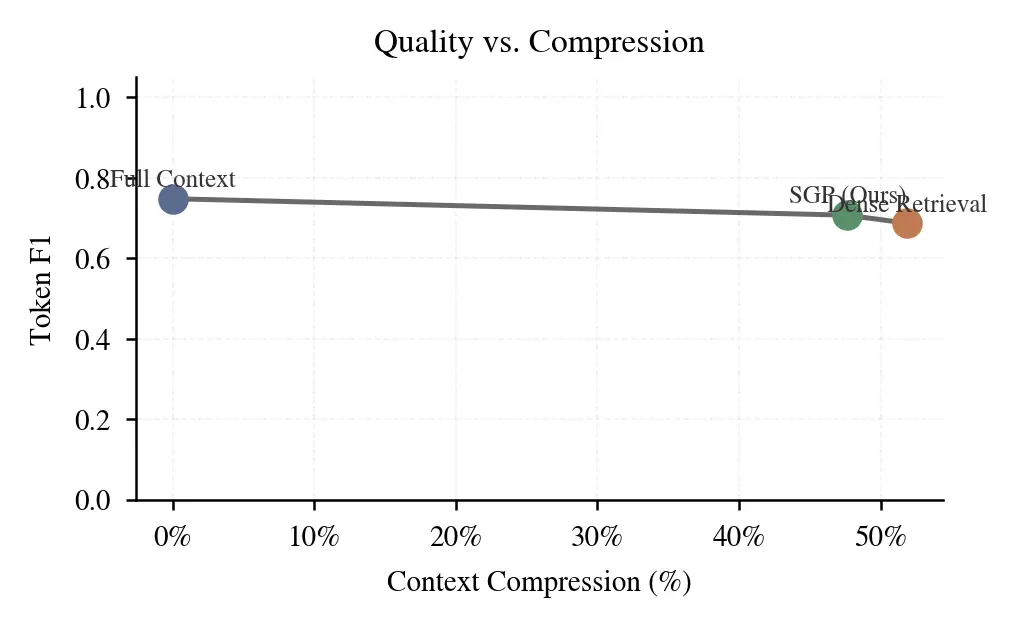 Figure 2: Quality vs Compression trade-off. SGP maintains high F1 scores even at high compression rates.
Figure 2: Quality vs Compression trade-off. SGP maintains high F1 scores even at high compression rates.
Latency Analysis
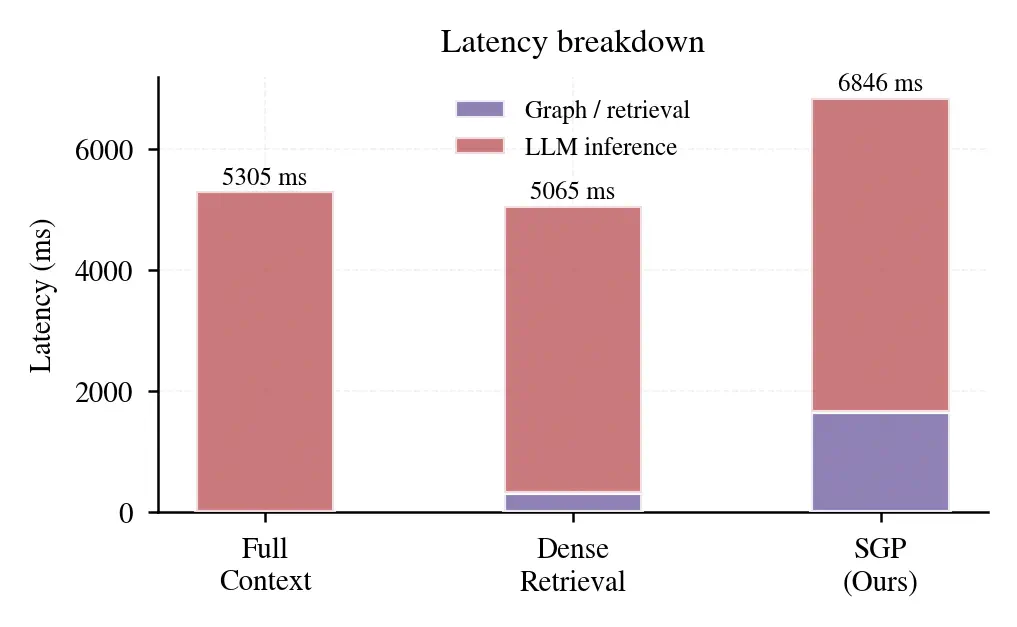 Figure 3: Latency breakdown showing minimal spectral scoring overhead compared to LLM inference savings.
Figure 3: Latency breakdown showing minimal spectral scoring overhead compared to LLM inference savings.
Resources
Citation
@article{sgp2026,
title={Spectral Graph Pruning for Context Optimization in Retrieval-Augmented Generation},
author={Gawade, Mayuri and Bavadekar, Aditya and Bhalerao, Shreyash and Bharat, Sarvesh and Bhandari, Chetan and Kokane, Chandrakant},
journal={arXiv preprint},
year={2026}
}